When I use an AI assistant for legal work, the first thing I do is give it the actual text of the statute. Not a summary, not whatever the model absorbed during training, but the current statutory language as published by the California Legislature. This is not a novel insight. It is the most basic version of a technique the AI community calls "grounding," and more specifically, retrieval-augmented generation, or RAG. You retrieve the authoritative source material and put it in front of the model before it generates a response. The model still does the reasoning, but it is reasoning about real text rather than a half-remembered approximation of it.
The problem is that grounding only works if you have the primary law in a format the AI can actually ingest. And that turns out to be harder than it should be. I went looking for a publicly available, regularly updated collection of California statutory text that I could use as a reference corpus. I did not find one. Westlaw and Lexis have the text, but it is behind a paywall and neither offers a public API for downloading statutory text at scale. The state's leginfo website lets you browse individual sections, but it is not designed for pulling down an entire code at once. I looked at legal data projects, open-source repositories, academic datasets. Nothing I found fit the requirement of being complete, current, and available in a format an AI can work with.

What I did find, eventually, is that the California Legislature publishes the entire statutory database as a single downloadable archive. It is a roughly 764-megabyte ZIP file containing data tables and XML content files for every active section of every California code. It is official. It is free. And as far as I can tell, almost nobody is using it for this purpose, which is surprising given how much attention legal AI hallucination has received.
I wrote a script that downloads that file, parses the database tables, and writes each of the 30 California codes out as clean plain text, one file per code, in proper statutory order with structural headings. Then I set up a free GitHub Actions workflow to run the script every night. If the Legislature has updated anything, it commits the changes automatically. The repository is public, at github.com/johnakelly-yahoo-com/california-codes. Anyone can use it.
The practical payoff is straightforward. When I point the AI at the actual text of the relevant code, it can still get the reasoning wrong, but it is no longer fabricating the source material. That eliminates a common category of hallucination: the kind where the statute the AI cites does not say what the AI claims it says, or does not exist at all. By constraining the input to only the authoritative source, the model has no reason to invent a statute because the answer is either in the text or it is not.
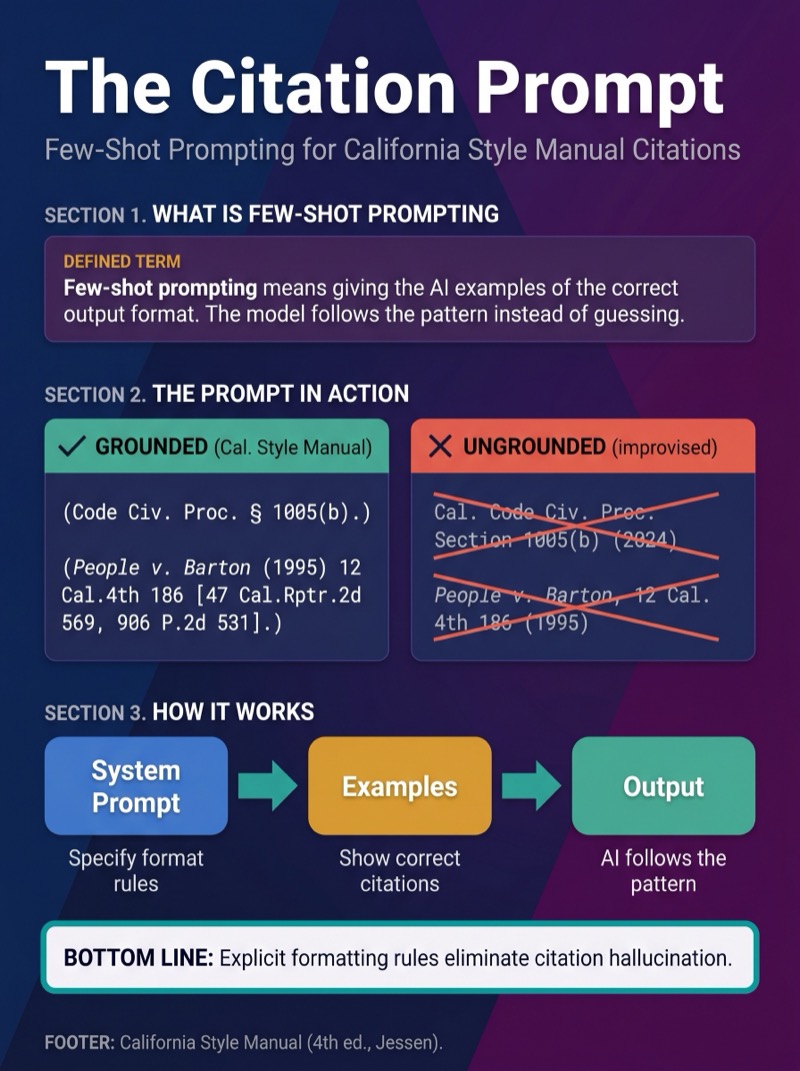
Giving the AI the statute text is only half of it. The other half is telling the AI how to cite what it finds. My system prompt includes an instruction that specifies California Style Manual citation format: year before the case name, parallel citations in brackets, no year for code sections or Rules of Court. When the AI writes "(Code Civ. Proc. § 1005(b).)" instead of some improvised format, that is not because it memorized the California Style Manual during training. It is because I told it the format and gave it examples — what the AI community calls few-shot prompting. The grounding works the same way in both directions: authoritative source material constrains the substance, few-shot examples constrain the output. The AI does not have to guess at either one.
Make this text accurate pursuant to the California Style Manual,
Fourth Edition, by Edward W. Jessen.
Put the year before the case citations.
Make sure the parallel cite is bracketed.
Do not include years for code section citations.
Do not include years for Rules of Court citations.
CASE CITATION:
(People v. Barton (1995) 12 Cal.4th 186
[47 Cal.Rptr.2d 569, 906 P.2d 531].)
CODE SECTION:
(Code Civ. Proc. § 1005(b).)
RULE OF COURT:
(Cal. Rules of Ct., Rule 3.1300(b).)This is not a replacement for Westlaw or Lexis. It does not include case law, annotations, or secondary sources. What it does is solve a specific, well-defined problem: if you are going to use AI to work with California statutes, you need the AI to have access to the actual statutes. That sounds so simple it barely seems worth saying, but the gap between "the AI should have the real text" and "here is a maintained, current source of the real text in a usable format" turns out to be where most practitioners get stuck. They either trust the AI's training data and risk hallucination, or they copy-paste individual sections by hand, which does not scale.
I could not find anyone else who had built this, which is the part that still surprises me. The data has been sitting on the Legislature's website for years. The tools to automate the pipeline are free. The need is well-documented. If someone else has done this and I missed it, I would genuinely like to know about it.

The research supports the approach. Stanford's study of legal AI tools found that Lexis+ AI and Westlaw AI hallucinate in 17 to 33 percent of queries, even with retrieval-augmented generation designed to anchor the output in real sources. (Magesh et al., Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools (2025) J. Empirical Legal Studies 1.) A March 2026 benchmark study went further and found that retrieval quality, not the choice of AI model, is the primary driver of whether a legal AI system gets the answer right. Most hallucinations in production systems, the authors concluded, are induced by retrieval failures. (Butler & Butler, Legal RAG Bench (Mar. 2, 2026) arXiv:2603.01710.) Get the retrieval right and the model follows. Get it wrong and no amount of model sophistication will save you.

And this is not a theoretical problem. Earlier this month, the Sixth Circuit sanctioned an attorney whose appellate briefs contained fabricated quotations attributed to real cases. The briefs had been drafted using Westlaw's CoCounsel. The court found three citations where "purported direct quotations do not appear in their cited sources" and could not locate any authority containing "the same or substantially similar language." (U.S. v. Farris, 6th Cir. Apr. 3, 2026.) This was not ChatGPT. This was the tool lawyers are paying for precisely because it is supposed to be grounded in real legal databases. The repository is there. It updates every night. And for anyone working with AI on California law, it is one less reason for the model to make things up.



